
输入输出(I/O)是在主存和外部设备(磁盘,终端,网络等)之间拷贝数据的过程。所有语言的运行时系统都系统高级大带缓冲区的IO函数,在高级IO函数工作良好的时候,没有必要使用系统级IO。
Unix I/O
可以把Uninx文件看作就是一个m个字节的序列,所有的IO设备。如网络,磁盘,终端都被模型化为文件,而所有的输入输出都被当作对应文件的读写来执行。这种将设备优雅地映射为文件的方式,允许Unix内核引出一个简单、低级的应用接口,称为 Unix IO。
打开文件。一个应用程序要求内核打开相应的文件来访问一个IO设备,内核会返回一个小的非负整数,称为文件描述符(fd),在对此文件的操作依赖于这个整数型的描述符。内核记录文件打开的文件的所有信息,而程序只记住这个描述符即可。
Unix shell为每个进程在开始时就打开三个文件:标准输入(0),标准输出(1),标准错误(2)(所以可以理解Linux系统中输出重定向的1,2的意义了)。头文件 unistd.h 定义了常量 STDIN_FILENO, STDOUT_FILENO, STDERR_FILENO来代替现实的描述符值。
- 改变当前的文件位置。对于打开的文件,内核保持一个文件位置k,相当于offset,初始为0。代表文件位置是从文件开头起始的字节偏移量,应用程序可以通过 seek 操作设置当前文件的 k。
- 读写文件。读写文件就是从文件拷贝数据到存储器,或者从存储器拷贝数据到文件。
- 关闭文件。应用完成了对文件的访问之后,它就通知内核关闭这个文件。内核释放打开这个文件时创建的数据结构,并将这个描述符恢复到可用的描述符池中。无论一个进程因为何种原因终止,内核都会关闭所有打开的文件,并释放它们的存储器资源。
打开和关闭文件
通过调用 open 函数来打开一个已经存在的文件或者创建一个新文件,open的函数声明如下:
|
可以看法函数的类型为int,即一个整数型的文件描述符,若返回为 -1 则表示出错。flag参数指明程序以何种方式访问文件,其取值有如下几种:
- O_RDONLY
- O_WRONLY
- O_RDWR
- O_CREAT
- O_TRUNC
- O_APPEND
分别代表只读,只写,可读可写,新建文件,文件存在就截断它,写之前设置文件位置到结尾(即追加内容)。flag参数可以是一个或者多位的或。
mode参数代表新建文件的访问权限位。对于打开一个文件,参数值为0即可。对于新建文件则要复杂一些。
作为上下文的一部分,每个进程都有一个umask,它是通过调用 umask函数来设置的。当进程通过带 mode 参数的open 函数调用来创建新文件时,文件的访问权限位被设置为 mode & ~umask。关于打开关闭文件参考下面的示例:
#include <fcntl.h> |
mask函数的声明在 sys/stat.h 中,其声明如下:
mode_t umask (mode t mask) |
读写文件
读写文件的write和read函数声明如下:
#include <unistd.h> |
read成功返回读取的字节数,EOF则返回0,错误返回-1;write写成功则返回写的字节数,错误返回-1。write函数在之前已经使用过很多次了。
注意上面的函数声明,可以发现里面有 size_t 和 ssize_t 两种类型,他们的区别是 size_t 定义为 unsigned int 而 ssize_t 定义为 int。因为读写的返回值要考虑到出错的情况返回-1,为了返回这个-1使得读写的最大值减少了一半,从4GB到了2GB。
可以想到读写可能遭遇到传送的字节数比参数要求的少的情况,这些不足值不表示错误,在读写磁盘文件时,只在读最后一次到EOF时才会遭遇不足值,在网络编程中和读取终端文本行时可能遭遇不足值。在网络应用中,必须通过反复调用read 和 write 处理不足值,直到所有的字节都传送完毕。
RIO包(Robust IO)
RIO包称为健壮的IO包,会自动处理上面提到的不足值的情况,在网络程序中,RIO提供了方便,健壮和高效的IO。
这应该不是标准库中的包,是CSAPP中引入的,这里不细讲了,有兴趣的可以去CSAPP Page 599看。
读取文件的元数据
文件的元数据包括文件的大小,inode,权限,时间等信息,这些信息保存在一个结构体中,内核为每个打开的文件描述符创建一个保存元数据的结构。可以使用 stat 和 fstat 函数获取这个结构。函数的声明如下:
#include <unistd.h> |
调用成功返回0,错误则返回-1。这两个函数的区别通过参数可以看出来了,stat使用文件名作为参数,而fstat使用文件描述符作为参数。第二个参数都是一个stat结构体的指针。stat结构体定义如下:
/* Metadata returned by the stat and fstat functions */ |
其中的st_mode 编码了文件访问许可位和文件类型,Unix提供的宏指令根据这个成员来确定文件类型,其提供的宏中常用的如下:
| 宏指令 | 描述 |
|---|---|
| S_ISREG() | 这是一个普通文件吗? |
| S_ISDIR() | 这是一个目录文件吗? |
| S_ISSOCK() | 这是一个网络套接字文件吗? |
注意它们都是宏,而不是函数。下面是一个使用示例:
#include <unistd.h> |
共享文件
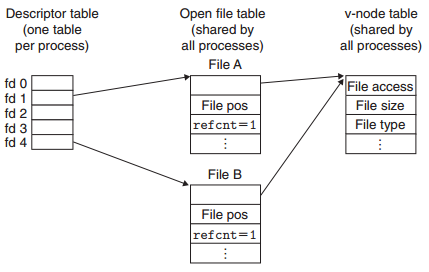
Unix内核使用三个相关的数据结构表示打开的文件,它们是文件共享的基础。
- 文件描述表。 每个进程有自己独立的描述符表,它的表项是由进程打开的文件描述符来索引的,每个打开的描述符表项指向文件表中的一个表项。
- 文件表。打开文件的集合由一张文件表来表示,所有的进程共享这张表。该表的表项包括当前文件位置,引用计数,以及一个指向v-node表对应表项的指针。
- v-node表。也是所有进程共享的表,该表包含stat结构中的大部分信息,比如st_mode 和 st_size。
一个进程使用open调用两次打开同一个文件,会在文件描述符表和文件表创建两个表项,但是会指向同一个v-node表项。理解文件位置信息保存在文件表中很重要,一个进程两次打开同一个文件,它们拥有自己文件位置不会相互影响。如下图所示,fd1 和 fd4是打开的同一个文件,所以指向同一个v-node项:
考虑一下之前看过的多进程情况,fork产生的子进程会获得(拷贝)父进程的文件描述符表,那么父子进程的文件描述符表项指向的文件表的表项是相同的,即是同一个文件位置。下图有利于理解这个场景。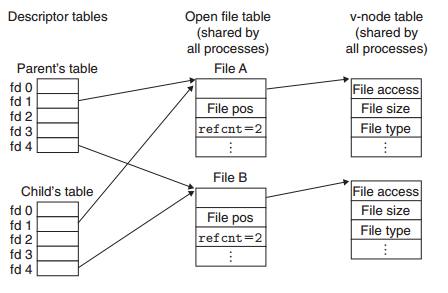
所有内核会在父子进程都关闭了某个文件描述符之后,才会删除相应的文件表项。
标准IO
ANSI C定义了一组高级输入输出函数,称为表标准IO库(libc),为程序员提供了Unix IO 的高级别实现。最常用的是gnu维护的glibc。它提供对应的 fopen, fclose, fread, fwrite, fgets,fputs,以及复杂的格式化函数scanf和 ·sprintf。
标准IO库将一个打开的文件模型化为一个流。对于程序员来说,一个流就是一个指向FILE类型的结构的指针。每个ANSI C程序开始时都打开三个流:stdin, stdout, stderr,它们定义在 stdio.h 中。
类型为FILE的流是对文件描述符和流缓冲区的抽象。
至此我们了解了低层次的Unix IO函数和较高级别的ANSI C标准IO函数,大多数程序员在他们的职业生涯中只适用标准IO,而从不涉及Unix IO函数,如果可以,确实应该这样做。
但是在网络编程中,标准IO可能存在一些限制,某种意义上说标准IO流是全双工的,能同时执行输入和输出,然而对流的限制和对套接字的限制,有时候会互相冲突:
- 跟在输出函数之后的输入函数,如果中间没有插入对fflush, fseek, fsetpos 或者 rewind 的调用,一个输入函数不能跟随在一个输出函数之后。 fflush 函数清空与流相关的缓冲区,后三个函数使用 Unix IO的lseek函数来重置当前的文件位置。
- 跟在输入函数之后的输出函数。如果中间没有插入 fseek, fsetpos或者rewind的调用,一个输出函数不能跟在一个输入函数之后,除非输入函数遇到了一个EOF。
由于网络应用的限制,对套接字使用 lseek 是非法的。对于第一个限制可以在每个输入操作之前刷新缓冲区来满足,对于第二个限制,只能对同一个打开的套接字描述符打开两个流,一个用来读,一个用来写。这是一个比较深的部分,这里不细讲了,感兴趣的可以去看 CSAPP Page611。内容不多。
在网络编程中(网络套接字)不要使用标准IO函数进行输入和输出,推荐使用健壮的RIO函数。
完。