
链接(linking)是将各种代码和数据部分收集起来并组合成为一个单一文件的过程,这个文件可以被加载到存储器并执行。
链接可以是在编译时执行(静态链接),或者在加载时执行,甚至在运行时执行(后两者均为动态链接)。在现代操作系统中,链接由链接器(linker)自动执行。
链接器使得分离编译成为可能。可以把程序分解为更小、更好管理的模块,可以独立的修改和编译这些模块,只需要简单重新编译它们,然后重新链接应用,而不需要重新编译其他文件。
一次编译过程
假设我们有两个源代码文件,它们的作用是交换两个元素。
main.c
void swap(); |
swap.c:
extern int buf[]; |
这个交换程序有点奇怪,不过这只是一个示例程序,奇怪也无所谓。我们知道要编译这两个文件使用下面的命令:
gcc -O2 -g -o p main.c swap.c |
其中-O2表示使用第二级的优化,一些参数的使用可以参考文档. 下面讲一下gcc整个编译生成可执行文件的过程。我们把GCC称为编译驱动程序。
- 编译驱动程序首先运行C预处理程序(cpp),它将 .c 文件翻译成一个ASCII码的中间文件(main.i文件)。
- 驱动程序运行C编译器(ccl),将 .i 文件翻译成一个ASCII汇编语言文件(main.s文件)。
- 驱动程序运行汇编器(as),将 .s 文件翻译成一个可重定位目标文件(main.o文件)
- 最后运行链接程序(ld),将main.o 和 swap.o 以及一些系统目标文件组合起来,创建一个可执行目标文件。
静态链接
Unix ld是一个静态链接器(static linker)。它以一组可重定位目标文件和命令行参数作为输入,生成一个完全链接的可加载和运行的可执行目标文件作为输出。输入的可重定位目标文件有各种不同的代码和数据节组成。为了构造可执行文件,链接器必须完成两个主要工作。
- 符号解析。目标文件定义和引用符号,符号解析的目的是将每个符号引用刚好和一个符号定义联系起来。
- 重定位。编译器和汇编器生成从0开始的的代码和数据节。链接器通过把每个符号定义与一个存储器位置联系起来,然后修改所有对这个符号的引用,使它们指向这个存储器位置,从而重定位这些节。
生成目标文件分三种:
- 可重定位目标文件
- 可执行目标文件
- 共享目标文件,一种特殊的可重定位目标文件。
编译器和汇编器生成可重定位目标文件,链接器生成可执行目标文件。
不同的系统生成的目标格式各不相同。最早的Unix系统使用 a.out 的格式,System V Unix早期版本使用一般目标文件格式(COFF)。Windows NT 使用的是COFF的一种变种叫可移植可执行(PR)格式,现代Unix系统使用的是Unix可执行和可链接格式(ELF: executable and linkable format)。下面分析一下ELF的格式。
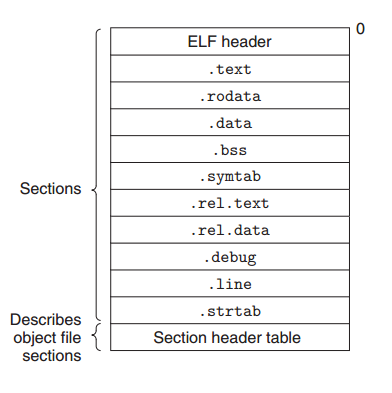
其中ELF头以一个16字节的序列开始,这个序列描述生成该文件的系统的字的大小和字节顺序。加载ELF头和节头部表之间的都是节,其中比较重要的节如下:
- .text:已编译程序的机器代码
- .data:已初始化的全局C变量,局部C变量保存在栈中,不在此节中出现
- .bss:未初始化全局变量。在目标文件中这个 节不占据实际空间,仅仅是一个占位符。bss是block started by symbol的首字母缩写,只是被沿用了,可以看成是 better save space。
- .symtab:一个符号表(symbol table),存放在程序中定义和引用的函数和全局变量的信息。
目标文件的符号表可以用gun readelf工具读取,一般的Linux系统都已经安装了 binutils,可以直接执行。
readelf -a main.o |
符号和符号表
每个可重定位目标模块m都有一个符号表,它包含m所定义和引用的符号的信息。在链接器的上下文中,有三种不同的符号:
- 由m定义并能被其他模块引用的全局符号.全局链接器符号对应于非静态的C函数及定义为不带static属性的全局变量。
- 由其它模块定义并被m模块引用的全局符号。这些符号称为外部符号(external),对应于定义在其他模块中的C函数和变量。
- 只被m定义和引用的本地符号。有的本地链接器符号对应于带static属性的C函数或全局变量。本地符号在m中随处可见,但是不能被其他模块引用。
要认识到本地连机器符号和本地程序变量的不同。本地非静态变量的符号在运行时在栈中被管理,链接器对此类符号不感兴趣。有趣的是定义为带有C static属性的本地过程变量是不在栈中管理的。编译器为其在 .data 和 .bss 中为每个定义分配空间,并在符号表中创建一个有唯一名字的本地链接器符号。这也是static变量特性的由来。
下面看一个例子,下面是一个模块中定义的两个函数:
int f() { |
这种情况下,编译器在 .data 节中为两个整数分配空间,并导出(export)两个唯一的本地链接器符号给汇编器。比如用 x.1 表示f中的定义,用 x.2 表示 g 中的定义。并且编译器会把初始化为0的变量放在 .bss 节而不是 .data 节,所以函数f中定义的x的实例存储在 .bss 节中。
C程序中使用static属性在模块内部隐藏变量和函数声明。C源代码文件扮演模块的角色。任何生命带有static属性的全局变量或者函数都是模块私有的,任何不带static属性的声明的全局变量和函数都是公有的,可以被其他模块访问。尽量用static属性来保护你的变量和函数。
符号表 symtab由汇编器构造,这张表包含一个条目的数组,其格式如下:
typedef struct [ |
其中name是字符串表中的偏移,指向符号的以null结尾的字符串名字。value是符号的地址。对于可重定位的模块来说,value是距定义的目标的节的起始位置的偏移。对于可执行目标文件,该值是一个绝对运行时地址。size是目标的大小以字节为单位。type通常是数据或者函数。
每个符号都和某个节相关联,由section字段表示,section还可能是三个特殊的伪节:ABS代表不该被重定位的符号,UNDEF(有的编译器为NOTYPE)表示未定义,即为本目标模块中引用,却在其他地方定义的符号;COMMON表示还未被分配位置的未初始化数据目标。
可以自己用readelf分析一个简单的 .o 文件,看看symtab的内容,更容易理解。
符号解析
链接器解析符号引用的方法是将每个引用与它输入的可重定位目标文件的符号表的一个确定的符号定义联系起来。对于定义和引用在同一个文件的符号,解析非常的简单明了。编译器会确保每个模块中本地符号只有一个定义,还能确保静态本地变量,它们也有本地链接器符号,且拥有唯一的名字。就像之前的 f() 和 g() 中分别定义的 static int x 在符号表中会添加一个后缀以作区分。
对于全局符号的解析比较麻烦,当编译器遇到一个不在当前模块定义的符号时,它会假设该符号在其他某个模块中定义,生成一个链接器符号表条目,并将它交给链接器处理。如果链接器在所有的输入模块都找不到该符号的定义,就输出一条错误并终止。
另一种可能的错误是多个目标文件可能会定义相同的(全局)符号,这种情况下,链接器要么报错误并停止,要么以某种方法确定一个定义并抛弃其他定义。Unix系统采用的方法涉及编译器,汇编器和链接器之间的协作,这样可能给不警觉的程序员带来一些麻烦。
Java 和 C++都允许重载方法,是因为编译器将每个唯一的方法和参数列表组合编码成一个对链接器来说唯一的名字。这个过程叫做mangling。C++和Java都是用兼容的毁坏策略。一个毁坏的名字由名字的字符的整数数量加原始名字组成,方法则由原始方法名加__(两个下划线)加毁坏的类名加每个参数的单个字母编码。比如
Foo::bar(int x, long y)被编码为:bar_3Fooil。
在编译时,编译器向汇编器输出每个全局符号(包括变量和函数),这些符号分为强和弱。函数和已经初始化的全局变量是强符号,未初始化的全局变量是弱符号(初始化为0被视为强符号),这些信息隐含在可重定位目标文件的符号表中。根据符号的强弱,Unix链接器使用下面的规则处理多重定义的符号:
- 不允许有多个强符号
- 如果有一个强符号和多个弱符号,那么选择强符号
- 如果有多个弱符号,那么从这些弱符号中任意选择一个
根据规则如果定义一个全局变量而没有初始化,如果其他模块有初始化的全局变量,那么链接器会安静地选择另一个模块中定义的强符号。有多个弱定义的时候会造成一些不易察觉的运行时错误,这种错误发生时很难理解。
当重复的符号定义有不同的类型时(链接阶段没有变量的类型信息),可能会导致一些意外的值覆盖。看下面的例子,两个源文件main.c 和foo.c。
main.c
|
foo.c
double x; |
代码很简单,main中定义了两个int符号x,y,但是在foo中定义了一个double的符号。按照main中定义的x是一个强符号,所以foo.c中引用的是main.c中的x,使用一个double值(8字节)覆盖了main中x及之后的4个字节,也就是用 -0.0 覆盖了x和y两个位置。
好在现在gcc(我的是4.8.3)会在编译这两个文件时提出一个warning。Warning: alignment 4 of symbol x' in /tmp/ccXksCfL.o is smaller than 8 in /tmp/ccWrh6NU.o。当然,对于warning,我们一般是无视的~~~为了防止这种安静的错误,可以使用gcc的 -fno-common 的选项调用,这样对于重复符号定义会报错,并编译失败。
这一部分可以看CSAPP Page 455-466的示例。
链接器使用静态库来解析引用
一些库常编译为 .o .a 文件用于静态链接,关于编译自己的 .a 文件可以查看CSAPP 458-459 页的部分。这里记录一下使用静态库解析引用的过程。
在符号解析阶段,链接器从左到右按照它们在编译驱动程序(GCC)命令行上出现的相同的顺序扫描可重定位目标文件和存档文件(.a)。在扫描中,链接器维护一个可重定位目标文件的集合 E,一个未解析符号集合 U,以及一个在前面输入文件已经的定义的符号集合 D,在初始时,E、D、U都是空的。Unix链接器的工作算法如下:
对命令行的输入文件,如果是一个目标文件,那么很简单,直接将其添加到E,相应修改U和D反映该文件的符号定义和引用。如果文件是一个存档文件,链接器尝试匹配U中未解析的符号和有存档文件成员定义的符号。如果存档文件成员m定义了一个符号来解析U中的一个引用,则也把m添加到E中。扫描所有的文件,那些不包含在E中的成员目标文件都将被丢弃(存档中的)。完成输入文件的扫描后,如果U是非空的,那么链接器将输出一个错误并终止。如果U是空的了,它会合并和重定位E中的目标文件,从而构建输出的可执行文件。
可惜的是,这个算法会导致一些令人困扰的链接错时错误。因为命令行中的顺序变得非常重要。如果定义一个符号的库出现在引用这个符号的目标文件之前,那么引用就不会被解析而链接失败。
关于库的一般准则是将它们放在命令行的结尾,并且如果库不是独立的,那么他们必须排序。有时候为了满足以来需要,可以在命令行中重复库。具体示例比较麻烦,请参考 CSAPP Page 460最后一部分。
基本完,后面重定位。