![]()
包括创建进程,执行程序和进程终止,还有进程属性的各种ID,以及它们如何受到进程控制原语的影响,最后还会介绍解释器文件,进程会计机制等。
进程标识
每个进程都有一个非负整型表示的唯一进程ID,进程ID标识符总是唯一的。虽然是唯一的,但是进程ID是可以复用的,当一个进程终止后,其进程ID就成为复用的候选者。大多数Unix系统实现延迟复用算法,使得赋予新建进程的ID不同于最近终止进程的ID。所以我们可以认为一段时间内,一个进程ID唯一代表那一个进程。
系统中有一些专用进程,比如ID为0的进程通常是调度进程,常常称为交换进程(swapper),该进程是内核的一部分(调度进程是内核的核心),它并不执行任何磁盘上的程序,因此也被称为系统进程。进程ID为1的通常是 init 进程,在自举(bootstrap)过程中由内核调用,此进程负责在自举内核后启动一个UNIX系统。init进程绝不会终止,它是一个普通的用户进程(而不是内核进程),但它以超级用户特权运行。(在某些Unix实现中,进程ID为2的是页守护进程(page daemon),它负责支持虚拟存储器系统的分页操作。
通过一些函数可以获得进程ID:
#include <unistd.h> |
上面的函数都没有出错返回,其中euid 和 egid 表示有效用户ID和有效gid。 getppid() 是获取父进程的ID,这是很重要的。
fork
#include <unistd.h> |
可以看出,这一部分的函数多是包含在 unistd.h 头文件中,因为这里的进程操作都是对 Unix 系统适用的,故在uni(x)std 中。
fork函数在之前已经介绍过了,它最重要的特征是一次调用有两个不同的返回值,分别对应父进程和子进程的返回值。fork出来的子进程是父进程的副本,子进程获得父进程数据空间,堆和栈的副本,但是父进程和子进程并不共享这些存储空间部分,父子进程只共享正文段(.text)。
注意,这个副本并不是一fork就复制这些区域,而是使用了 写时复制技术,因为在fork之后常跟随着exec调用执行一个独立的程序,所以对fork的实现并不执行一个父进程数据段、栈和堆的完全副本,而是将这些区域有父子进程共享(注意上面说的并不共享这些区域),内核将它们的访问权限改为只读,如果父子进程中的一个试图修改这些区域,则内核只为修改区域的那块内存制作一个副本,通常是虚拟存储系统中的一页。
如果fork之后不是执行一个 exec 调用,而是使用共享的正文段继续执行,这时候要理解子进程是父进程的一个复制,因为子进程得到父进程数据区域的副本,所以子进程会在fork之处继续续执行。父子进程执行的顺序是不确定,这取决于内核所使用的调度算法。
对于
char a[] = "hello world"定义的字符串,strlen计算不包含终止 null 字节的字符串长度,而sizeof则计算包括终止 null 字节的缓冲区长度。它们的另一个区别是 strlen 需进行一次函数调用,而 sizeof 因为缓冲区已用已知字符串进行初始化,其长度是固定的,所以 sizeof 是在编译时计算缓冲区长度。注意如果是char *a = "hello word"则是不一样的,所以字符数组名和字符串指针在某些运算并不是完全一样的。
题外:1. 标准输出默认缓冲区(终端设备)是行缓冲的(换行符冲洗),当将标准输出重定向到一个文件时,则它是全缓冲的。 2. 大多数 exit 实现不再流的关闭方面自找麻烦,因为进程即将终止,那时内核将关闭在进程中已打开的所有文嘉描述符。在库中关闭这些只是增加开销而不会带来任何益处。
fork的文件共享
对于打开文件,文件描述符表之前的文章已经说过了,父进程所打开文件描述符都被复制到子进程中(包括标准输入输出),父进程和子进程每个相同的打开描述符共享一个文件表项。需要注意的是,父子进程共享同一个文件偏移量。所以如果父子进程同时写一个共享的文件描述符,因为它们共享偏移量,所以他们会交叉写入。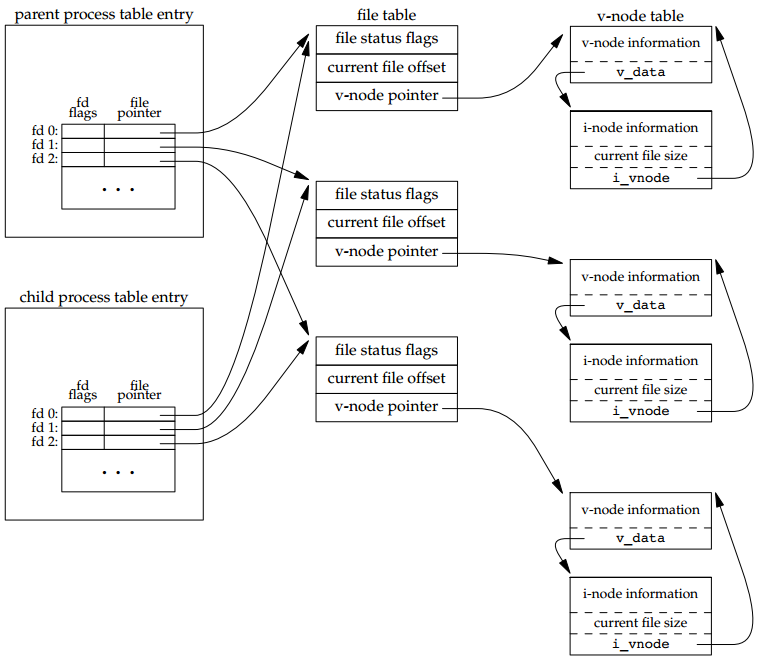
wait waitpid
我们知道父子进程的执行顺序是随意的,由内核调度程序而定。很多时候父进程要知道子进程是否执行结束,或者要等待子进程执行完。当一个进程正常或异常中止时,内核就向其父进程发送 SIGCHLD 信号。因为子进程中止是个异步事件,所以这种信号也是内核向父进程发的异步通知,父进程可以忽略该信号,或者提供一个该信号发生时即被调用执行的函数。
对于父进程已经终止的所有进程,它们的父进程都改变为init进程。
这里使用 wait 和 waitpid 函数调用等待子进程运行。
#include <sys/wait.h> |
在一个子进程终止前,wait使其调用者阻塞,直到某个子进程中止,则取得该子进程的中止状态写入 statloc 参数,并立即返回,如果该进程没有任何子进程,则立即出错返回。
waitpid则可以指定一个特定的子进程,也可以指定一个选项,使调用者不阻塞。如果两个函数的参数 statloc 是一个整形指针,如果 statloc 不是一个空指针,则终止进程的终止状态就存放在它所指向的单元内,如果不关心终止状态,则可以将该参数指定为空指针。
对于存储在 statloc 中的终止状态,可以使用 <sys/wait.h> 中定义的宏来查看,这些宏使用 WIF 前缀。
- WIFEXITED(status)
- WIFSIGNALED(status)
- WIFSTOPPED(status)
- WIFCONTINUED(status)
void pr_exit(int status) { |
对于 waitpid 中的 pid参数有一些特定的取值,有下面的特殊参数:
- pid == -1 : 等待任一子进程,此时 waitpid 与 wait 等效
- pid > 0 : 等待进程ID与pid相等的子进程
- pid == 0 : 等待组ID等于调用进程组ID的任一子进程
- pid < -1 : 等待组ID等于pid绝对值的任一子进程
waitpid 的第三个参数能进一步控制其操作,它或者是0,或者是下面的常量:
- WCONTINUED
- WNOHANG
- WUNTRACED
最常用的是指定 WNOHANG 则若由pid自定的子进程并不是立即可用的,则 waitpid 不阻塞,此时其返回状态为0。通过 WUNTRACED 和 WCONTNUED 选项支持作业控制。这在后面的章节了解。
其他还有 waitid, wait3, wait4 几个函数。
exec
在fork调用创建新的子进程后,常在子进程中调用一种 exec 函数执行另一个程序,调用exec函数时,该进程执行的程序完全替换为新程序,而新程序则从其main函数开始执行。因为exec并不创建新进程,所以前后的进程ID并未改变,exec只是用磁盘上的一个程序替换了当前进程的正文段、数据段和堆、栈段。
总共有7中不同的exec函数可以调用,都被称为exec函数,它们只是各自的参数略有不同,这些exec函数使得Unix系统进程控制源于更加完善,用fork可以创建新的进程,用 exec 可以初始执行新的程序,exit函数和wait函数处理终止和等待终止,这些都是我们需要的基本的进程控制原语。
#include <unistd.h> |
前4个函数取路径名作为参数,后两个函数取文件名作为参数,最后一个取文件描述符作为参数。对于filename参数,如果包含 / ,则将其视为路径名,如果是文件名则根据PATH环境变量,在指定的各目录搜寻可执行文件。
题外:一般不推荐将当前目录 . 添加到PATH中,虽然有人喜欢这样做,但有些人认为这样有安全性问题。个人也不推荐将 . 追加到PATH中,执行当前目录下的可执行文件使用 ./command 是更好的选择。
这些函数后缀: l 表示 list,即参数列表, v 表示vector,即矢量(数组)。带 l 后缀的参数中有一个特殊的 (char *)0 参数,这种语法显式地说明最后一个命令行参数之后跟随了一个空指针(还记得命令行参数部分讲过的,最后一个命令行参数是一个空指针吗),如果直接使用一个 0 则会被解释为整型参数,如果一个整型数的长度与 char * 的长度不同,那么exec 函数的实际参数可能出错,所以要显示调用类型转换。
一个值得关心的问题是,在调用 exec 函数时,对于打开的文件流如何处理(因为就进程数据段都被新的可执行文件替换了)。实际上,对已经打开文件的处理与每个文件描述符(分fd)的执行时关闭(close-on-exec)标志值有关。若设置了此值,则在执行 exec 时关闭该描述,否则该描述符仍是打开的。除非特地用 fcntl 设置了该标志,否则系统的默认操作时在exec后仍保持这种描述符打开。
POSIX.1明确要求在exec时关闭打开目录流。在exec前后实际用户ID和实际组ID保持不变,而有效ID则取决于所执行程序的设置ID位是否设置了。
这上面的7个函数中,只有 execve 是内核的系统调用,另外6个都是库函数,他们最终都要调用该系统调用(execve)。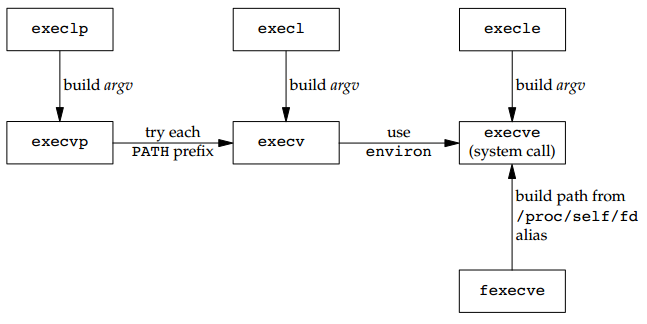
因为exec函数调用使用新的程序替换了就得代码段,所以在执行完这个程序后进程就退出了,不再执行父进程的代码段了。所以可以直接在父进程的后续代码使用 waitpid 等待子进程结束(不需要判断pid是否是父进程)。
解释器文件
现在所有个Unix系统都支持解释器文件(interpreter file),这种文件是文本文件,不过其起始行有特殊的格式要求,示例如下:
#! pathname [optional-argumant] |
如果对Linux脚本比较熟悉的话应该见过很多这样的脚本了。pathname通常是绝对路径,对它不进行什么特殊处理(不使用PATH路径搜索)。对这种文件的识别是由内核作为exec系统调用处理的一部分来完成的。内核使用 exec 函数的进程实际执行的并不是该解释器文件,而是在该文件第一行中 pathname 所指定的文件,然后将该解释器文件作为解释器的输入,注意区分解释器文件和解释器。 #! 这一行(第一行)被称为 shebang 也称为 Hashbang,常翻译为组织行。
system 函数
可以用system函数执行一条命令, ISO C定义了system函数,但是其操作对系统的依赖性很强。POSIX.1包括了system 接口,它扩展了ISO C定义,描述了system在POSIX.1环境中的运行行为。
#include <stdlib.h> |
使用system而不是直接使用fork+exec的优点是,system进行了所需要的各种出错处理及信号处理,使用更加简单方便。对于其更详细的内容就不在这介绍了。
进程会计
大多数Unix系统提供了一个选项以进行进程会计(processing accounting)处理,启用该选项后,每当进程结束时内核就写一个会计记录,典型的记录包含总量较小的二进制数据,一般包含命令名、所使用的CPU时间总量,用户ID和组ID、启动时间等。但是所有的标准都没有对进程会计进行过说明,所以所有实现都有令人厌恶的差别。不同的系统提供了不同的函数调用。
会计记录一般写到指定的文件中, FreeBSD和MaxOS中,该文件通常是 /var/account/acct,在Linux中该文件是 /var/account/pacct (但是在centos中并未找到该文件 -_-||),可以用 fread 读取指定的问题见,读取到一个 struct acct 结构体中。这部分用权当了解一下吧。
进程调度
插一句用户标识的部分,使用 getlogin函数获得登录用户名。如果一个用户有多个登录用户名,这些登录名又对应着同一个用户id,那么此时要用 getlogin函数获得登录名:
#include <unistd.h> |
如果在守护进程调用此函数则会失败,因为守护进程没有连接到用户登录时所用的终端。注意不要用环境变脸 LOGNAME 获取用户名,因为环境变量是可以随便设置的。
Unix系统历史上对进程提供的知识基于调度优先级的粗粒度的控制。调度策略和调度优先级是由内核确定的。进程可以通过调整 nice 值选择以更低的优先级运行。 SUS中nice值的范围在 0~ (2 * NZERO) - 1 之间,nice值越小,优先级越高。进程可以通过nice函数获取或更改它的nice值,进程只能影响自己的nice值,不能影响其他进程。
#include <unistd.h> |
参数 incr(increase) 被增加到调用进程的nice值上,如果incr太大,则直接降到最大合法值。类似地如果incr太小(负数)则自动提高到最小合法值。若调用成功返回新的nice值,出错返回-1,所以 incr为0则返回现有的nice值。Linux的默认nice值应该是0。
进程时间
任一进程可以通过调用 times 函数(注意与time的区别)获得自己以及已终止子进程的墙上时钟时间(wall clock time),用户CPU时间,和系统CPU等值。在shell中执行time命令也会这些相关的时间,注意time命令不是返回当前的时间,date命令才是返回时间的命令。
#include <sys/times.h> |
times函数返回流逝的墙上时钟时间(以时钟滴答数为单位)。此值是相对于过去的某一时刻度量的,所以不能用其绝对值而必须使用其相对值,即两次调用times的差才是有意义的。所有clock_t值都是用 _SC_CLK_TCK (clk: clock, tck: tick)转换成秒。
#include <unistd.h> |
参考: